Machine learning, un'immagine vale più di mille parole






Editing automatico dei file, classificazione delle immagini, individuazione degli oggetti all’interno di foto e video, monitoraggio di asset e prodotti, fino al riconoscimento di emozioni e azioni basato sulla Face Recognition. Sono queste, secondo gli Osservatori del Politecnico di Milano, le applicazioni più promettenti dell’intelligenza artificiale che sfrutta il machine learning per l’analisi dei dati.
Di Lorenzo Capitani | Su PRINTlovers 88
Perché certi siti chiedono di riconoscere lettere astruse, di selezionare semafori, strisce pedonali, biciclette e autobus o di cliccare su “Non sono un robot”? Non è solo per verificare che siate esseri umani e non computer con cattive intenzioni (i cosiddetti bot), ma anche per addestrare un’intelligenza artificiale.
I captcha (così si chiamano quei piccoli quiz, da “Caught you!”, Ti ho beccato!), infatti, basati sul più classico test di Touring per distinguere computer dagli esseri umani, servono non solo per la sicurezza, ma soprattutto per insegnare alle macchine a leggere e a riconoscere oggetti specifici all’interno di una fotografia. Fantascienza da Matrix? Assolutamente no, come vedremo.
Nel 1997 i ricercatori di AltaVista, per impedire ai bot di aggiungere URL al loro motore di ricerca in modo fraudolento, ebbero l’idea di sfruttare al contrario le caratteristiche del programma di OCR dello scanner Brother che avevano in ufficio. Se un testo è confuso, si sovrappone a un altro, i caratteri cambiano o il fondo non è omogeneo, pensarono, la macchina non è più in grado di interpretarlo, ma un uomo sì. Questa intuizione venne sfruttata anche dall’Università Carnegie Mellon di Pittsburgh quando avviò la digitalizzazione della sua biblioteca ed ebbe l’idea di sottoporre agli utenti sotto forma di captcha le parole dubbie individuate dall’OCR: se una persona riesce a individuare correttamente una parola nota, allora individuerà anche quella ignota e quando tre persone daranno la stessa risposta, questa potrà essere archiviata dal sistema come corretta. Funzionò, tanto che nel settembre del 2009 questa tecnologia fu acquistata da Google.
Fare esperienza
Oggi l’intelligenza artificiale e il machine learning, ovvero il meccanismo per cui i sistemi apprendono e migliorano le loro performance e capacità di risposta in base ai dati che utilizzano, sono quasi ovunque. Da Siri che risponde in modo adeguato alle domande, imparando da cosa le si chiede e da quanto la sua risposta sia soddisfacente, fino alla bacchetta magica di Photoshop che riconosce un soggetto e sa isolarlo dal fondo (01), non solo in base alla differenza di colore, ma perché sa riconoscere e distinguere i singoli elementi. Ma l’intelligenza artificiale subentra anche quando interagiamo con le banche, acquistiamo online o utilizziamo i social media, leggiamo le notizie o scegliamo un film su Netflix, fino all’auto che riconosce cartelli stradali e corsie. Anche fuori dal contesto con il quale si sta interagendo in quel momento e in modo inaspettato, continuamente entrano in gioco meccanismi di machine learning per rendere la nostra esperienza efficiente, facile e sicura. Pensiamo alle immagini: il servizio gratuito di Google per la loro archiviazione, ad esempio, se da un lato offre spazio per immagazzinare le nostre foto, dall’altro le usa per imparare. Fedeli al patto faustiano per cui “se non paghi, il prodotto sei tu”, siamo noi che autorizziamo, in modo più o meno spontaneo e inconsapevole, l’uso delle nostre informazioni che non sono solo quelle che condividiamo sui social, ma sono soprattutto tutte le altre: dagli allegati delle mail ai documenti che storiamo nel cloud, fino alle immagini delle telecamere di sicurezza che passano e si archiviano nella rete. Al di là degli aspetti di privacy e di profilazione, che poi passano in secondo piano tra autorizzazioni capestro (vuoi il servizio? dammi accesso ai dati) o concesse con leggerezza, l’intelligenza artificiale scandaglia e apprende da tutto quello che le viene dato in pasto; la potenza computazionale e la bontà dell’algoritmo fanno il resto. In una sorta di nastro di Moebius, l’AI analizza i dati, li elabora, apprende e fornisce a sua volta dati che riutilizzati vengono analizzati, elaborati e così via. Un esempio sono i filtri di certe app, come FaceApp, che alterano l’aspetto dei nostri selfie. La foto va nei loro server, viene immagazzinata insieme a milioni di altre, elaborata in base ai filtri impostati e rimandata nell’app: già solo tenere la versione elaborata o eliminarla significa insegnare all’AI a far meglio. Lo stesso accade con i nuovi filtri neurali presenti nella versione 2021 di Photoshop che da questa release lavora sempre a stretto contatto con il cloud Adobe, tanto che il “Salva con nome” lo propone di default come destinazione predefinita. I filtri “pelle liscia” o “sostituzione cielo” sono estremamente realistici, ma a lasciare a bocca aperta per l’accuratezza sono il “trasferimento trucco”, per cui si applica un trucco da una foto target caricata, e il “ritratto intelligente”, che altera l’espressione di un viso in una gamma che va dalla felicità alla rabbia. E non è un caso che questi filtri chiedano all’utente, a effetto applicato, se sia soddisfatto o meno.
Imparare dai propri errori
Ma come fa un computer a imparare? Sintetizzando al massimo, lo fa classificando, elaborando e apprendendo dai feedback sul suo operato, secondo algoritmi più o meno supervisionati. La logica che sfrutta la continua correzione dei risultati sulla base di un modello dato, anche con l’intervento umano, è oggi la più usata. Come spiega Oracle, “come un bambino impara a identificare i frutti memorizzandoli da un libro illustrato, così l’algoritmo viene addestrato a partire da un set di dati che è già etichettato e classificato”. Al contrario, gli algoritmi non supervisionati “utilizzano un approccio indipendente, in cui il computer impara da solo a identificare processi e schemi senza nessuna guida: in questo caso, è come se un bambino imparasse a identificare i frutti osservando colori e modelli, senza memorizzare i nomi con l’aiuto di un insegnante: cercherà le somiglianze tra le immagini e le suddividerà in gruppi, assegnando a ciascun gruppo la nuova etichetta”. È così che funziona il Face ID di Apple: legge un viso, ne fa una mappa e la salva. Ogni volta che si vuole sbloccare il dispositivo, confronta il viso in quel momento con la mappa salvata. Il rating di riconoscimento fa il resto: se assomiglia al modello, il telefono si sblocca, e tutto quello che differiva viene salvato per perfezionare la mappa. Così, ad esempio, il telefono si sblocca che si indossino o meno occhiali.
È ovvio che i due metodi finiscono per migliorarsi l’un l’altro. Una volta che viene identificata una nuova etichetta, questa diventerà a sua volta un modello. Il processo è sintetizzato dalla formula proposta nel 2017 da Robin Bordol, CEO di Crowdflower:
AI = TD (Training Data) + ML (Machine Learning) + HITL (Human In The Loop).
L’Image Recognition
Oggi il panorama dell’AI sta decollando e i diversi motori di machine learning per l’analisi dei dati operano prevalentemente grazie a reti neurali per l’elaborazione di foto, video e testi che riescono a riconoscere forme, colori, fino addirittura a seguire oggetti in movimento. Secondo gli Osservatori del Politecnico di Milano le applicazioni più promettenti sono l’editing automatico dei file, la classificazione delle immagini, l’individuazione degli oggetti all’interno di foto e video, il monitoraggio di asset e prodotti, fino al riconoscimento di emozioni e azioni basati sulla Face Recognition. Innanzitutto, dall’immagine, composta da pixel, viene estratto un gran numero di caratteristiche (feature). Senza andare troppo nel dettaglio, una volta che ogni immagine è stata convertita in migliaia di caratteristiche (feature), si può iniziare ad addestrare un modello. Nel caso di foto che rappresentano, per esempio, dei prodotti integri e dei prodotti fallati, possiamo addestrare la macchina a riconoscere una delle due categorie. Più immagini si utilizzano per ogni categoria, meglio un modello può essere addestrato: una volta che ha imparato, può riconoscere un’immagine sconosciuta. Prendiamo l’immagine (02), se alla prima elaborazione non riconosce il logo Apple e lo scambia per la silhouette di mela morsicata (l’abbiamo testato e non succede), dopo che è stato istruito, lo riconoscerà correttamente.
Google Vision AI
Facciamo un esperimento.
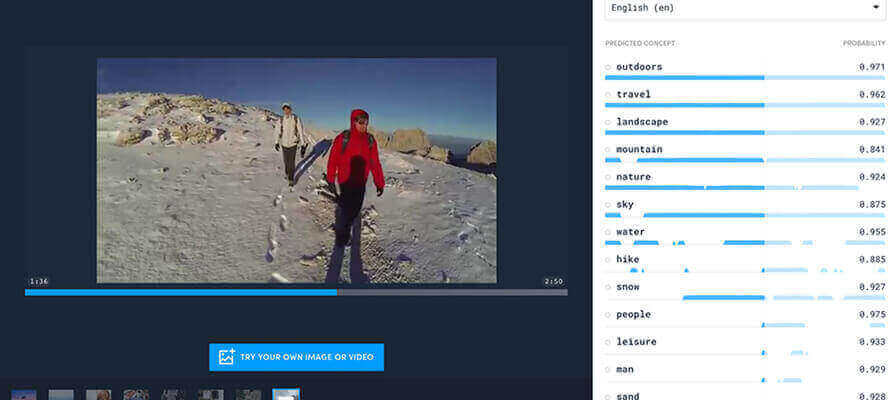
Alla pagina Google mette a disposizione un simulatore del suo Vision AI. Nella foto, in pochi secondi, riconosce che c’è una persona, nello specifico una donna, e che indossa un cappello (addirittura riconosce che è una fedora), un cappotto e delle collane. A ciascun dettaglio individuato assegna un tasso di riconoscimento e così l’algoritmo ci dice che ci sono delle scarpe al 94%, degli occhiali da sole all’87%. Ma non si ferma qui, associa delle etichette (borsa, alberi, trench, fashion), classifica le espressioni facciali (joy), verifica quanto l’immagine sia sicura rispetto a contenuti sensibili (sesso, violenza, contenuti razziali), crea una mappa dei colori con i valori in RGB e la loro copertura in percentuali ed esclude i colori di fondo per evitare falsi positivi. Infine, isola le singole parti e ne mappa le coordinate. Già questo piccolo esperimento svela le potenzialità dello strumento. Dategli in pasto tutte le immagini dei vostri prodotti e insegnategli a riconoscere i dettagli che vi interessano, correggetelo quando sbaglia e vi ritroverete una moltitudine di dati da usare. Come? Prendiamo un e-commerce di moda: sfruttando questi dati, potrei costruire una gallery in base ai colori, distinguere foto indossate da still-life, spingere capi con il logo in determinati mercati o verso particolari utenti che apprezzano questi dettagli, aggregare in base al tipo di prodotto o di genere, e così via senza che nessuno abbia speso tempo a classificare le immagini e, cosa altrettanto importante, senza che nessuno abbia predeterminato cosa cercare. E questo equivale a esplorare aree di business nuove o non considerate.
Il sistema Google di base lavora ad ampio spettro e ha il vantaggio di offrire tutta la forza dell’ecosistema e dell’esperienza del gigante di Mountain View e la sua capacità di calcolo e di integrazione con gli altri suoi servizi in Cloud. Vision AI può lavorare in modo silente sulle immagini archiviate nei suoi server, materializzare i dati estratti e metterli a disposizione. Dopo di che si decide quale approccio avere, se supervisionato o meno, arrivando perfino a poter intervenire sull’algoritmo. Una volta estratti i dati si può procedere per inclusione o esclusione di certi risultati (per esempio un bikini non lo mostro nell’e-commerce di certi mercati) o sul best match, ovvero quanto un’immagine si avvicina a un esempio dato. Un esempio tangibile è il tool Reverse Image Search nella home di Google. Provate a dargli in pasto una foto e lui troverà all’istante tutte quelle simili, fino a trovare la stessa in altre varianti di dimensione. Su strumenti come questi posso basare in automatico i suggerimenti tipici come gli abbinamenti e gli You May Also Like.
Altri approcci
Un’alternativa altrettanto potente è Amazon Rekognition, attivabile direttamente in AWS, probabilmente il servizio di cloud computing e hosting di Amazon più diffuso, in grado di identificare oggetti, persone, testo, scenari e attività in foto e video e riconoscere i contenuti anche nei testi. Gli usi anche qui sono molteplici e dipendono dal business: si va dal riconoscimento facciale (per esempio personaggi famosi, persone autorizzate, dipendenti), di oggetti e scene, all’individuazione di contenuti vietati per effettuare moderazioni o verifiche umane, dal riconoscimento di testi all’individuazione dei propri prodotti tra le foto pubblicate sui social media o presenti sugli scaffali di un punto vendita per ricerche di mercato. Interessante l’esperimento fatto da Nike filmando a filo strada tutti i partecipanti alla maratona di Tokyo 2019 per identificare e classificare i marchi e modelli di scarpe usati dai partecipanti. Amazon Rekognition è direttamente integrata con Amazon Augmented AI (Amazon A2I) per poter implementare facilmente la revisione umana per un rilevamento di immagini inappropriate. Amazon A2I fornisce un flusso di lavoro di revisione umana integrato per la moderazione di immagini, che consente una facile revisione e validazione delle previsioni da Amazon Rekognition. Tra le piattaforme indipendenti, la principale è sicuramente Clarifai, che adotta un approccio supervisionabile con tanto di workflow per gestire l’apprendimento in base a specifiche esigenze dell’utente e adotta soluzioni particolarmente potenti per il riconoscimento di immagini, video e testi in contesti specifici come il food. Non solo è in grado di individuare singoli prodotti o ingredienti, ma anche preparazioni e piatti. Per il travel, invece, da una foto riesce a estrapolare anche il luogo, i servizi offerti o caratteristiche di location, hotel e residenze. La forza degli algoritmi di Clarifai è proprio il saper lavorare per ambiti circoscritti, con caratteristiche note e peculiari, alzando di conseguenza la precisione dei risultati. Un esempio è il riconoscimento automatico di capi e accessori o la classificazione delle texture e dei pattern per il fashion. Anche con i testi non se la cava male, OCR compreso: l’approccio in questo caso non è solo riconoscere e rendere il testo editabile, ma anche classificarlo in base al contenuto per la moderazione di contenuti indesiderati, cercare parole e concetti chiave o fare analisi di web reputation.
L’architettura dell’informazione
Passare dall’avere poco, magari estratto a fatica manualmente, a questa enorme messe di dati può disorientare. Prima di chiedersi cosa classificare, è opportuno chiedersi perché farlo, magari partendo da un’esigenza specifica. Il bello di queste soluzioni è che non seguono processi lineari: sono come delle reti e per di più scalabili. Ci si può muovere in ogni direzione e cambiare facilmente la profondità di analisi, basta modificare l’algoritmo e riprocessare i file. Potrei iniziare solo dal tagging per la classificazione e poi sfruttare l’identificazione degli oggetti cui legare delle azioni. È quello che succede per esempio con l’app di Ikea, dove nelle foto d’ambiente agli oggetti sono stati associati degli hot spot che rimandano alle scheda prodotto con le relative varianti colore e la possibilità di aggiungerli direttamente al carrello. Come si vede, questi strumenti, per quanto fortemente basati sulle macchine, richiedono sempre l’intervento umano per raffinare il risultato. È un cambio di paradigma: lascio alla macchina il lavoro più oneroso, lungo e a basso valore e mi concentro sull’addestramento dell’algoritmo.
Un valido approccio che può essere seguito è quello di procedere per step. Prendiamo i tag della foto (03) presa da Shutterstock: ha associate più di 200 parole chiave generiche che vanno dall’azzeccato “donna” all’incomprensibile “quadrante”, mancano del tutto non solo “giglio”, ma anche “fiore”, e ci sono anche “usura” e “vintage”. Se il mio contesto è la moda, scremati gli errori, aggiunto i tag in base a una specifica semantica: quell’”usura” diventerà il “stone washed” del jeans, la trama della fascia sarà identificata come “losanga”; questo perché l’AI esamina i segni visivi (vettori, forme e colori) e li paragona con i modelli di riferimento ed è proprio sulle tassonomie, classificazioni e sulle localizzazioni che occorre lavorare.
AI a 360 gradi
Se sulle immagini questi automatismi risparmiano azioni ripetitive, pensate a cosa si può fare con un video, dove le immagini in movimento richiedono l’intervento quasi fotogramma per fotogramma. In questo caso Sensei, il motore di AI di Adobe, è davvero lo stato dell’arte. Abbiamo accennato sopra all’intelligenza artificiale applicata agli strumenti di Photoshop, ma è solo la punta di un iceberg. Quello che propone Adobe è un vero e proprio ecosistema, fatto di “piccole” funzionalità, come i filtri neurali di Photoshop, presenti nelle nuove release degli applicativi che semplificano il lavoro di grafici e creativi; ma soprattutto è fatto di potenti motori di elaborazione integrati nelle suite Experience Cloud e Marketing Cloud, la famiglia di prodotti per il business digitale, che consente di coprire end-to-end tutto il processo produttivo e distributivo riducendo i colli di bottiglia. Pensiamo a una libreria di immagini di prodotti archiviati sul DAM Adobe: Sensei può in automatico indentificare gli oggetti contenuti, isolarli, cropparli, ricavando dinamicamente foto per foto le coordinate di taglio, e poi creare altre rendition pronte alla distribuzione o preparate per un successivo riuso. Il vantaggio diventa esponenziale, ragionando sui video. Consideriamone uno editoriale per un sito e-commerce: Adobe copre le fasi dalla produzione – con l’editing e il montaggio del filmato, il riconoscimento dei dettagli (i prodotti), l’assegnazione di tag specifici per il CEO e il SEM del sito, l’applicazione di aree dinamiche che addirittura seguono i soggetti in movimento cui associare eventi – alla distribuzione, con la costruzione della pagina web che lo ospita e il CMS per l’erogazione del media in modo responsivo in base al device da cui si sta navigando indipendentemente dalle dimensioni e dalla forma dello schermo dell’utente (l’IA di Sensei arriva a rilevare il punto di fuoco e a operare i tagli di conseguenza, assicurando che il soggetto scelto sia sempre nitido e al centro della scena), e così via fino alla raccolta e all’analisi di tutti i dati classici degli analytics.
Oggi l’accesso ai dati si è molto semplificato, la consapevolezza del loro valore sta crescendo e sta portando a una trasformazione dei processi aziendali: occorre solo non lasciarsi spaventare dalla loro potenziale immensa vastità per imparare a navigare nel mare delle informazioni, senza trovarsi travolti o completamente all’asciutto.
08/10/2021


